4 Visualising Results for Multiple Stages
As well as visualising the results for a single stage, we might want to visualise the results over multiple stages. The basic overall results can be retrieved from a single call to the WRC results API, but to view the stage times and rankings across multiple stages requires retrieving detailed for each stage and then combining it into a single dataframe.
4.1 Load Base Data
To get the splits data from a standing start, we can load in the current season list, select the rally we want, look up the itinerary from the rally, extract the sections and then the stages and the retrieve the stage ID for the stage we are interested in.
To begin with, load in our WRC API helper functions:
source('code/wrc-api.R')
library(tidyr)Now let’s grab some data:
s = get_active_season()
eventId = get_eventId_from_name(s, 'arctic')
entries = get_rally_entries(eventId)
itinerary = get_itinerary(eventId)
sections = get_sections(itinerary)
stages = get_stages(sections)
stages_lookup = get_stages_lookup(stages)
stage_list = get_stage_list(stages)
stage_codes = stages$code
# To generate stage codes as an ordered factor:
# factor(stages$code, levels = stages$code)4.2 Retrieving Mutliple Stage Results
To being with, lets get the overall results at the end of each stage:
multi_overall_results = get_multi_overall(stage_list)
multi_overall_results %>% tail(2)## entryId stageTimeMs stageTime penaltyTimeMs penaltyTime totalTimeMs
## 530 21542 11203500 PT3H6M43.5S 0 PT0S 11203500
## 531 21569 11754200 PT3H15M54.2S 0 PT0S 11754200
## totalTime position diffFirstMs diffFirst diffPrevMs diffPrev stageId
## 530 PT3H6M43.5S 51 3773900 PT1H2M53.9S 696500 PT11M36.5S 1749
## 531 PT3H15M54.2S 52 4324600 PT1H12M4.6S 550700 PT9M10.7S 17494.2.1 Reshaping Overall Position Data
We can reduce the amount of data by casting the long raw result to a wide format, widening the data on a particular field of interest. For example, we can widen generate a wide dataframe describing overall positions, \({_S}o\) at the end of each stage, where a particular driver’s position is given as \({_S}o_i\):
multi_overall_wide_pos = multi_overall_results %>%
get_multi_stage_generic_wide(stage_list,
'position')
multi_overall_wide_pos %>% head(2)## entryId 1747 1743 1750 1751 1748 1745 1744 1742 1746 1749
## 1 21530 9 9 9 8 8 7 6 22 20 20
## 2 21531 5 5 5 5 5 5 5 5 5 54.2.2 Reshaping Overall Rally Time Data
We can also create a wide format report of the overall times, where each column gives the overall, accumulated rally time up to and including each stage, \({_S}T\); each cell then represents the accumulated time for a particular driver, \({_S}T_i\).
The times themselves appear in units of milliseconds, so first create a column corresponding to time in seconds, then widen using those values:
multi_overall_results = multi_overall_results %>%
mutate(totalTimeS = totalTimeMs/1000)
multi_overall_wide_time = multi_overall_results %>%
get_multi_stage_generic_wide(stage_list,
'totalTimeS')
multi_overall_wide_time %>% head(2)## entryId 1747 1743 1750 1751 1748 1745 1744 1742 1746 1749
## 1 21530 980.5 1960.5 2802.5 3351.0 4102.2 4955.9 5512.6 6876.6 7491.6 8095.8
## 2 21531 974.5 1942.7 2788.5 3335.1 4085.3 4938.9 5491.5 6275.6 6883.1 7491.1We note that with stages presented in order, the rally time is strictly increasing across the rows.
We further note that we can derive stage times from the overall rally times by calculating the columnwise differences \({_S}t={_S}T-{_{S-1}}T: 1<S<N\) for an \(N\) stage rally.
4.2.3 Reshaping Time to First Data
Another useful time is the time to first, which is to say, the gap, \({_S}GAP_i\). Noting that the overall rally leader may change at the end of each stage, this measure is essentially a rebasing measure relative to a particular position rather than a particular driver:
multi_overall_results = multi_overall_results %>%
mutate(diffFirstS = diffFirstMs/1000)
multi_overall_wide_gap = multi_overall_results %>%
get_multi_stage_generic_wide(stage_list,
'diffFirstS')
multi_overall_wide_gap %>% head(2)## entryId 1747 1743 1750 1751 1748 1745 1744 1742 1746 1749
## 1 21530 22.7 49.8 57.3 53.1 54.2 70.6 76.8 664.5 666.1 666.2
## 2 21531 16.7 32.0 43.3 37.2 37.3 53.6 55.7 63.5 57.6 61.5However, we could also calculate the gap to leader from the overall times, first by identifying the minimum accumulated time at each stage (that is, the minimum time, excluding null values, in each overall time column) and then by subtracting those values from each row in the overall times dataframe, which is to say:
\[ \textrm{GAP}_{i} = {_S}t_i - \textrm{min}({_S}T) \]
If we try to subtract a list of values (for example, \(\forall S \in [1 \le S \le N]: \textrm{min}({_S}T)\)) from an R dataframe, we need to tell R how we want that subtraction performed. Internally, the dataframe is represented as a long list of values made up from values in the first column, then the second, and so on. If we subtract a list of N values from the dataframe, the values are selected from the first N items in this long serialised version of the dataframe, then the next N values and so on.
So to subtract a “dummy” row of values from the dataframe, we need another approach. The purrr::map2df() function allows us to apply a function, in this case the subtraction - function, with a set of specified values we want to subtract, from each row in the dataframe.
So let’s create a set of values representing the minimum overall time in each stage. The matrixStats::colMins() function will find the minimum values by row from a matrix, so cast the stage time columns from the wide dataframe to an appropriately sized matrix and then find the minimum in each column, ignoring null values:
overall_m = as.matrix(multi_overall_wide_time[,as.character(stage_list)],
ncols=length(stage_list))
mins_overall = matrixStats::colMins(overall_m, na.rm=TRUE)
mins_overall## [1] 957.8 1910.7 2745.2 3297.9 4048.0 4885.3 5435.8 6212.1 6825.5 7429.6We can now subtract this “dummy row” of values from each row in the dataframe to find the gap to leader for each row on each stage:
purrr::map2_df(multi_overall_wide_time[,as.character(stage_list)],
mins_overall, `-`) %>% head(2)## # A tibble: 2 x 10
## `1747` `1743` `1750` `1751` `1748` `1745` `1744` `1742` `1746`
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 22.7 49.80000 57.3 53.10000 54.20000 70.60000 76.8 664.5 666.1
## 2 16.7 32 43.3 37.20000 37.3 53.60000 55.70000 63.5 57.6
## # … with 1 more variable: 1749 <dbl>Comparison with the “diffToFirst” times should show them to be the same.
4.2.4 Mapping Stage and Driver Identifiers to Meaningful Labels
To improve the look of the table, we might use stage codes and driver codes to label the columns and identify the rows.
To start with, we can map the column names that correspond to stage codes via a lookup list of stage ID to stage code values:
map_stage_codes = function(df, stage_list) {
# Get stage codes lookup id->code
stages_lookup_code = get_stages_lookup(stages, 'stageId', 'code')
#https://stackoverflow.com/a/34299333/454773
plyr::rename(df, replace = stages_lookup_code,
warn_missing = FALSE)
}
multi_overall_wide_time = multi_overall_wide_time %>%
map_stage_codes(stage_list)
multi_overall_wide_time %>% head(2)## entryId SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 21530 980.5 1960.5 2802.5 3351.0 4102.2 4955.9 5512.6 6876.6 7491.6 8095.8
## 2 21531 974.5 1942.7 2788.5 3335.1 4085.3 4938.9 5491.5 6275.6 6883.1 7491.1We can also create a function to replace the entry ID with the driver code. Note also the select statement at the end that puts the columns into a sensible order:
cars = get_car_data(entries)
map_driver_names = function(df, cars){
df %>%
merge(cars[,c('entryId','code')],
by='entryId') %>%
# Limit columns and set column order
select(-'entryId') %>%
# Move last column to first
select('code', everything())
}
multi_overall_wide_time = multi_overall_wide_time %>%
map_driver_names(cars)
multi_overall_wide_time %>% head(2)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 OGI 980.5 1960.5 2802.5 3351.0 4102.2 4955.9 5512.6 6876.6 7491.6 8095.8
## 2 EVA 974.5 1942.7 2788.5 3335.1 4085.3 4938.9 5491.5 6275.6 6883.1 7491.14.2.5 Rebasing Overall Times
We can rebase the overall times with respect to a particular driver in the normal way, calculating the difference between each row and the row corresponding to a specified driver:
example_driver = multi_overall_wide_time[2,]$code
overall_wide_time_rebased = rebase(multi_overall_wide_time,
example_driver, stage_codes,
id_col='code')
overall_wide_time_rebased %>% head(3)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 OGI 6.0 17.8 14.0 15.9 16.9 17.0 21.1 601.0 608.5 604.7
## 2 EVA 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 3 NEU -4.3 -2.2 -12.5 -8.0 -2.6 -18.7 -17.5 -37.6 -36.5 -41.74.2.6 Finding Changes in Rebased Gaps Across Stages
The rebasing operation essentially allows us to select a row of times for one particular driver and then subtract that row from every other row to give us a direct comparison of the gap between a specified driver and every other driver.
But we can also perform a consecutive column-wise differencing operation on the rebased times that allows to see how much time was gained or relative to a particular driver in going from one stage to the next (observant readers may note that this results in the rebased stage time for each stage…).
To subtract one column from the next, create two offset dataframes, one containing all but the first stage (first stage column) and one containing all but the last stage (final stage column). If we subtract one dataframe from the other, it gives us our column differences. Inserting the original first column back in its rightful place gives us the columnwise differences table:
#https://stackoverflow.com/a/50411529/454773
df = overall_wide_time_rebased
# [-1] drops the first column, [-ncol()] drops the last
df_ = df[,stage_codes][-1] - df[,stage_codes][-ncol(df[,stage_codes])]
# The split time to the first split is simply the first split time
df_[stage_codes[1]] = df[stage_codes[1]]
# Return the dataframe in a sensible column order
df_ %>% select(stage_codes) %>% head(3)## Note: Using an external vector in selections is ambiguous.
## ℹ Use `all_of(stage_codes)` instead of `stage_codes` to silence this message.
## ℹ See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
## This message is displayed once per session.## SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 6.0 11.8 -3.8 1.9 1.0 0.1 4.1 579.9 7.5 -3.8
## 2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 3 -4.3 2.1 -10.3 4.5 5.4 -16.1 1.2 -20.1 1.1 -5.2(A similar technique could be used to recreate stage times from the overall times.)
4.3 Visualising Overall Results
The overall stage results provides information regarding the overall times and positions at the end of each stage; the rebased overall times provide us with gap information from a specified driver to every other driver.
So how might we use exploratory data visualisation techniques to support a conversation with that data or highlight potential stories hidden within it?
4.3.1 Visualising First Position
One way of enriching the wide position table might be to highlight the driver in first position at the end of each stage. We can do this using the formattable::formattable() function.
First, let’s tidy up the overall position table:
multi_overall_wide_pos = multi_overall_wide_pos %>%
map_stage_codes(stage_codes) %>%
map_driver_names(cars)
multi_overall_wide_pos %>% head(2)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 OGI 9 9 9 8 8 7 6 22 20 20
## 2 EVA 5 5 5 5 5 5 5 5 5 5We can also reorder the table by the final stage position, as described by the last stage code in the stage_codes list. However, because we want to sort on a column name as provided by a variable, we need to use the !! operator to force the evaluation of the single variable value to the column name symbol (as.symbol()):
multi_overall_wide_pos = multi_overall_wide_pos %>%
dplyr::arrange(!!as.symbol(stage_codes[length(stage_codes)]))
multi_overall_wide_pos %>% head(2)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 TÄN 1 1 1 1 1 1 1 1 1 1
## 2 ROV 3 3 3 2 2 2 2 2 2 2Create a function to highlight the first position car:
library(formattable)
highlight_first = function (...)
{
formatter("span",
style = function(x) ifelse(x==1,
style(display = "block",
padding = "0 4px",
`color` = "black",
`column-width`='4em',
`border-radius` = "4px",
`background-color` = 'lightgrey'),
style()))
}And then use that function to help style the table:
multi_overall_wide_pos %>%
head(3) %>%
formattable(# Align values in the center of each column
align='c',
list(area(col = stage_codes) ~ highlight_first()))| code | SS1 | SS2 | SS3 | SS4 | SS5 | SS6 | SS7 | SS8 | SS9 | SS10 |
|---|---|---|---|---|---|---|---|---|---|---|
| TÄN | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| ROV | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| NEU | 4 | 4 | 4 | 4 | 4 | 3 | 3 | 3 | 3 | 3 |
4.3.2 Visualising Position Changes Over a Rally
Another useful way of summarising the positions is to chart showing the evolution of position changes.
The chart is constructed most straightforwardly from tidy (long format) data:
overall_pos_long_top10 <- multi_overall_wide_pos %>%
head(10) %>%
#gather(key ="Stage",
# value ="Pos",
# stage_codes)
# pivot longer replaces gather
pivot_longer(c(stage_codes),
names_to ="Stage",
values_to ="Pos")
overall_pos_long_top10 %>% head(3)## # A tibble: 3 x 3
## code Stage Pos
## <chr> <chr> <int>
## 1 TÄN SS1 1
## 2 TÄN SS2 1
## 3 TÄN SS3 1It will be convenient for the stage codes to be represented as ordered factors:
overall_pos_long_top10 = overall_pos_long_top10 %>%
mutate(Stage = factor(Stage,
levels = stage_codes))
overall_pos_long_top10$Stage[1]## [1] SS1
## Levels: SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10We can then create a bump chart style plot showing how each driver’s positioned changed across stages:
library(ggplot2)
pos_range = 1:max(overall_pos_long_top10$Pos)
g_pos = ggplot(overall_pos_long_top10, aes(x=Stage, y=Pos)) +
geom_line(aes(group = code)) +
# Invert scale and relabel y-axis
# https://stackoverflow.com/a/28392170/454773
scale_y_continuous(trans = "reverse",
breaks = pos_range) +
theme_classic()
g_pos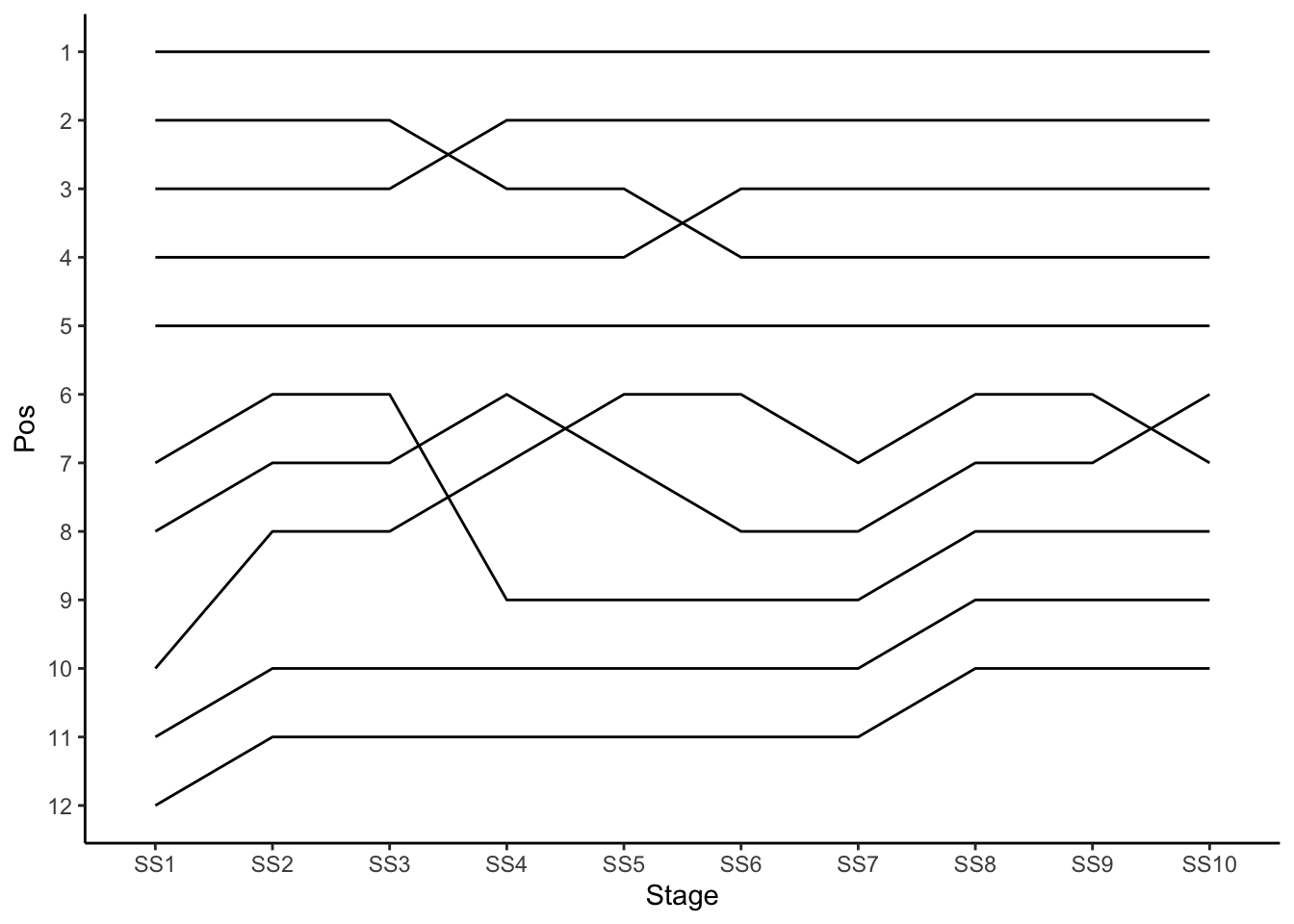
We can producing a cleaner chart by adding driver labels to the start and end of each line using the directlabels:geom_dl() function, as well as dropping the axes:
library(directlabels)
g_pos +
geom_dl(aes(label = paste0(' ',code)), # Add space before label
# Add label at end of line
method = list('last.bumpup',
# cex is text label size
cex = 0.5)) +
geom_dl(aes(label = paste0(code, ' ')), # Add space before label
# Add label at start of line
method = list('first.points', cex = 0.5)) +
theme_void()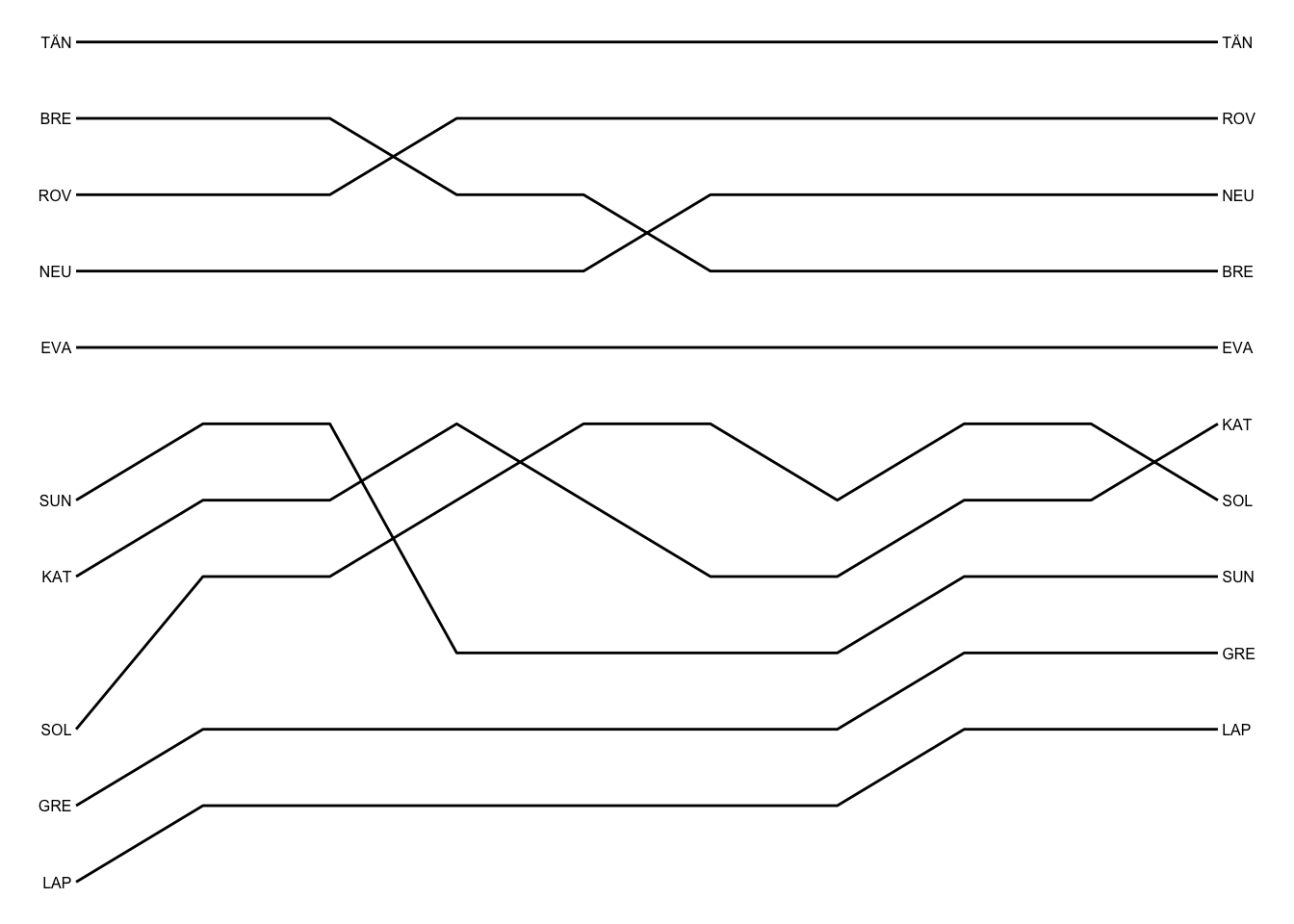
In the above chart, you may notice a gap at first stage position 6 where Ogier was originally placed. A more robust way to prepare the data for this sort of charts is to filter the data by class, for example limiting the data to cars in the WRC group/class, and then reranking the position by group/class. A finished position chart can then position the drivers by class ranking and use labels to overplot actual overall rally positions on stages where the overall stage position differs from the class rank.
4.3.3 Visualising Position Gains/Losses
To visualise position changes for a driver from one driver to the next, we can create a table of position differences. Let’s abstract out the code we used to find differences between columns in to a function:
coldiffs = function(df, cols, dropfirst=FALSE, firstcol=NULL){
cols = as.character(cols)
# [-1] drops the first column, [-ncol()] drops the last
df_ = df[,cols][-1] - df[,cols][-ncol(df[,cols])]
# The split time to the first split is simply the first split time
df_[cols[1]] = df[cols[1]]
# Return the dataframe in a sensible column order
df_ = df_ %>% select(cols)
if (!is.null(firstcol))
df_[, cols[1]] = firstcol
if (dropfirst)
df_[,cols][-1]
else
df_
}Let’s put that function through its paces. First, we can drop the first column:
coldiffs(multi_overall_wide_pos, stage_codes, dropfirst=TRUE) %>% head(2)## Note: Using an external vector in selections is ambiguous.
## ℹ Use `all_of(cols)` instead of `cols` to silence this message.
## ℹ See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
## This message is displayed once per session.## SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 0 0 0 0 0 0 0 0 0
## 2 0 0 -1 0 0 0 0 0 0Then we can retain the first column and replace it with a specified value:
coldiffs(multi_overall_wide_pos, stage_codes, firstcol=999) %>% head(2)## SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 999 0 0 0 0 0 0 0 0 0
## 2 999 0 0 -1 0 0 0 0 0 0We can now fund the position changes from stage to stage as well as tidying up the identifiers:
pos_diffs = multi_overall_wide_pos %>% coldiffs(stage_codes,
firstcol=0)
pos_diffs$code = multi_overall_wide_pos$code
# Reorder the columns by moving last column to first
pos_diffs = pos_diffs %>% select('code', everything())
pos_diffs %>% head(3)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 TÄN 0 0 0 0 0 0 0 0 0 0
## 2 ROV 0 0 0 -1 0 0 0 0 0 0
## 3 NEU 0 0 0 0 0 -1 0 0 0 0Note that we need to be careful with the sense of how we read this table: a negative position change means the driver has improved their position. It might be more meaningful to have position gain/loss, rather than strict position difference columns, where a positive value denotes an improved position:
pos_gains = pos_diffs
pos_gains[,stage_codes] = -pos_gains[,stage_codes[-1]]
pos_gains %>% head(3)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 TÄN 0 0 0 0 0 0 0 0 0 0
## 2 ROV 0 0 1 0 0 0 0 0 0 0
## 3 NEU 0 0 0 0 1 0 0 0 0 0One way of highlighting position changes is to use coloured up/down arrows:
updown = function(...){
formatter("span",
style = function(x) style(color = ifelse(x>0,
"green",
ifelse(x<0,
"red",
"lightgrey"))),
function(x) icontext(ifelse (x >0,
# i.e. gained position
"arrow-up",
ifelse (x < 0,
# Lost position
"arrow-down" ,
# No position change
"resize-horizontal"))))
}Let’s see how that works (note that we need to cast the table as.htmlwidget() in order to render the arrows appropriately :
pos_gains %>%
head(3) %>%
formattable(list(
area(col = stage_codes) ~ updown())) %>%
as.htmlwidget()We can extend the formatter to also display the number of positions gained or lost:
updown2 = function(...){
formatter("span",
style = function(x) style(color = ifelse(x>0,
"green",
ifelse(x<0,
"red",
"lightgrey"))),
function(x) icontext(ifelse (x >0,
# i.e. gained position
"arrow-up",
ifelse (x < 0,
"arrow-down" ,
"resize-horizontal")),
# Add in the pos change value
ifelse (x!=0, paste0('(',abs(x),')'),'')))
}Let’s see how it looks:
pos_gains %>%
head(3) %>%
formattable(list(
area(col = stage_codes) ~ updown2())) %>%
as.htmlwidget()Another way of visualising position changes is to create a simple summarising sparkline using the sparkline::spk_chr() function.
This requires us first to cast the data into a long format:
library(sparkline)
pos_gain_long_top10 <- pos_gains %>%
head(10) %>%
gather(key ="Stage",
value ="PosChange",
stage_codes)
pos_gain_long_top10 %>% head(3)## code Stage PosChange
## 1 TÄN SS1 0
## 2 ROV SS1 0
## 3 NEU SS1 0We can then generate sparklines showing position changes:
pos_gain_sparkline_top10 <- pos_gain_long_top10 %>%
group_by(code) %>%
summarize(spk_ = spk_chr(PosChange,
type ="bar"))
# We need to create an htmlwidget form of the table
out = as.htmlwidget(formattable(pos_gain_sparkline_top10))
# The table also has a requirement on the sparkline package
out$dependencies = c(out$dependencies,
htmlwidgets:::widget_dependencies("sparkline",
"sparkline"))
outNote that to render the sparkline, we need to cast the formatted table to an htmlwidget and also ensure that the required sparkline Javascript package is loaded into the widget.
One issue with the sparkline bars is that the scales may differ. For example, across different drivers, a position change of +1 for one driver may have the same height as a position change of +2 for another driver.
4.3.4 Per Driver Position Charts
As well as generating summary chapters over a set of drivers, we can also generate charts on a per driver basis, cf. sparkline charts.
For example, we can create a simple chart that captures a single driver’s position over several stages, optionally using the gt::ggplot_image() function to create an HTML embeddable image tag with the chart encoded as a data URI:
rovCode = get_person_id(cars, 'rov', ret='code')
get_pos_chart = function(df_long, code, embed=FALSE,
height=30, aspect_ratio=1, size=5) {
# Get the data for the specified driver
subdf = df_long[df_long['code']==code,]
ymax = max(10.6, max(subdf$Pos)+0.1)
g = ggplot(subdf,
aes(x=as.integer(Stage), y=Pos, group=code)) +
geom_step(direction='mid', color='blue', size=size) +
geom_hline(yintercept=0.8, linetype='dotted',
size=size, color='black') +
geom_hline(yintercept=3.35, linetype='dotted',
size=size, color='black') +
geom_hline(yintercept=10.5, color='darkgrey',
size=size) +
#scale_y_continuous(trans = "reverse") +
scale_y_reverse( lim=c(ymax, 0.8)) +
theme_void() + scale_x_continuous(expand=c(0,0)) #+
#theme(aspect.ratio=0.1)
if (embed)
gt::ggplot_image(g, height = height, aspect_ratio=aspect_ratio)
else
g
}
get_pos_chart(overall_pos_long_top10, rovCode)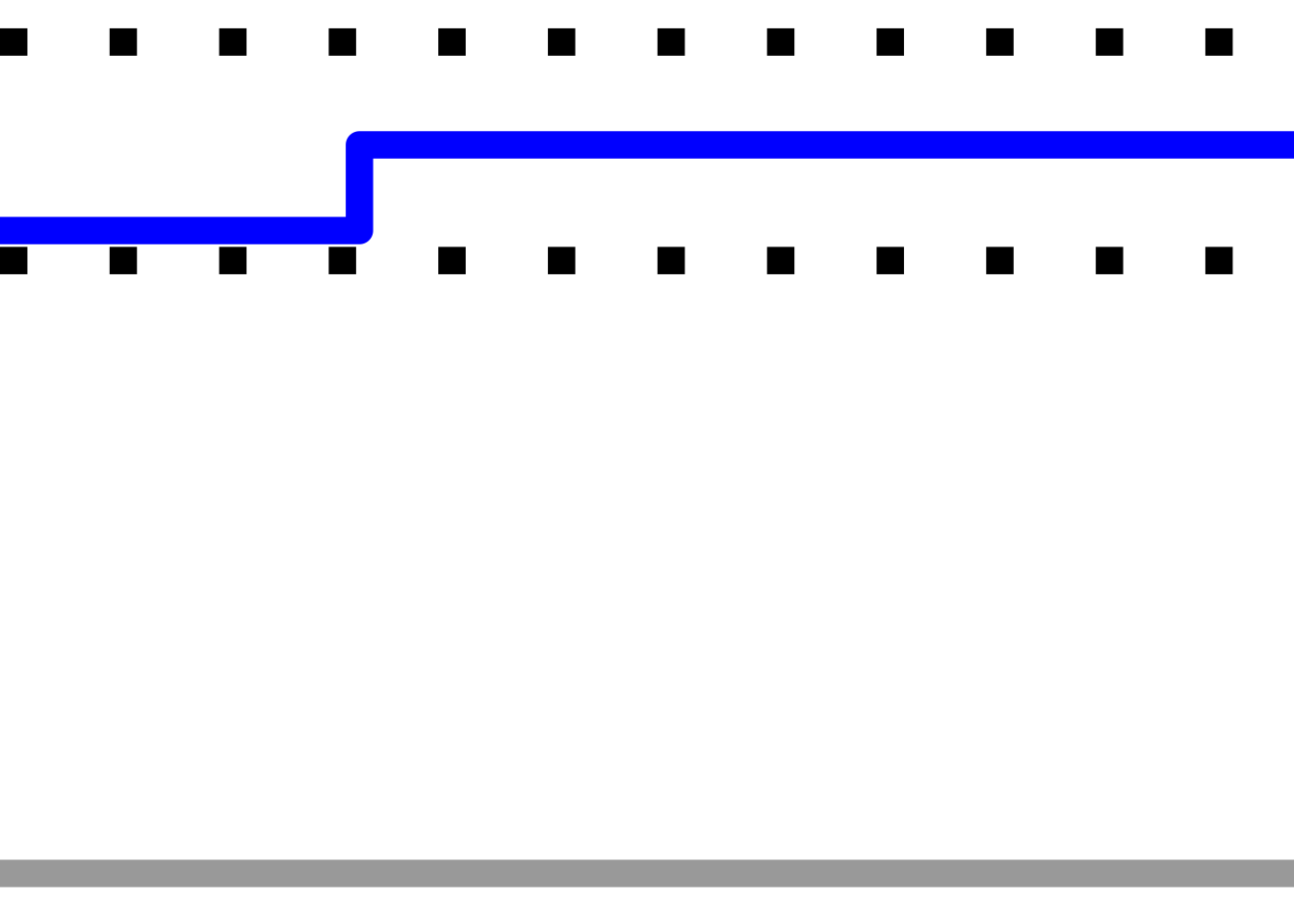
If we generate an image for each driver, we can then create a column of images to showing the change in position over the rally for each one on a row by row basis:
overall_wide_pos_top5 = multi_overall_wide_pos %>% head(5)
top5codes = overall_wide_pos_top5$code
gt_pos_plots = list()
# Iterate through each driver in the top 5
for (c in 1:length(top5codes)){
# Add each plot to the plot list
# The split is generated for the top 5
gt_pos_plots[[length(gt_pos_plots) + 1]] <-
get_pos_chart(overall_pos_long_top10, top5codes[c],
embed=T, aspect_ratio=3, size=5)
}We can then add the charts to the wide timing results dataframe as an extra column:
overall_wide_pos_top5$poschart = gt_pos_plots
formattable(overall_wide_pos_top5)| code | SS1 | SS2 | SS3 | SS4 | SS5 | SS6 | SS7 | SS8 | SS9 | SS10 | poschart |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TÄN | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |

|
| ROV | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |

|
| NEU | 4 | 4 | 4 | 4 | 4 | 3 | 3 | 3 | 3 | 3 |

|
| BRE | 2 | 2 | 2 | 3 | 3 | 4 | 4 | 4 | 4 | 4 |

|
| EVA | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |

|
# How do we suppress stripes in formattable tables?4.3.5 Visualising Time to First
A convenient way of visualising the gap to leader across stages is to create a sparkline using the sparkline::spk_chr() function. This function requires data in a tidy (long) format which is then grouped for each driver.
Let’s remind ourselves of what the data looks like:
multi_overall_wide_gap_top10 = multi_overall_wide_gap %>%
map_stage_codes(stage_list) %>%
map_driver_names(cars) %>%
dplyr::arrange(!!as.symbol(stage_codes[length(stage_codes)])) %>%
head(10)
multi_overall_wide_gap_top10## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 TÄN 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 2 ROV 10.6 20.4 26.1 21.2 23.6 25.0 23.3 24.1 19.2 17.5
## 3 NEU 12.4 29.8 30.8 29.2 34.7 34.9 38.2 25.9 21.1 19.8
## 4 BRE 3.6 16.2 23.6 22.4 28.9 42.8 50.6 53.4 54.0 52.6
## 5 EVA 16.7 32.0 43.3 37.2 37.3 53.6 55.7 63.5 57.6 61.5
## 6 KAT 19.9 38.8 47.5 46.6 52.4 74.5 83.8 94.4 93.2 97.8
## 7 SOL 31.1 45.9 50.5 49.4 51.3 62.7 80.4 86.8 84.2 99.0
## 8 SUN 18.8 34.5 46.9 54.1 70.9 82.1 98.2 109.3 117.3 129.0
## 9 GRE 41.8 65.8 84.7 94.6 112.1 134.3 156.5 181.8 200.5 219.4
## 10 LAP 42.8 88.2 123.4 146.9 186.2 215.8 239.3 288.8 327.1 367.0We can create the required long form data from the wide gap table as follows, retrieving just the top 10 drivers based on the gap on the final stage, for convenience:
overall_long_gap_top10 <- multi_overall_wide_gap_top10 %>%
gather(key ="Stage",
value ="Gap", stage_codes)
overall_long_gap_top10 %>% head(3)## code Stage Gap
## 1 TÄN SS1 0.0
## 2 ROV SS1 10.6
## 3 NEU SS1 12.4With the data in the appropriate form, we can create the sparkline, using a bar chart format:
overall_long_gap_top10 <- overall_long_gap_top10 %>%
group_by(code) %>%
summarize(spk_ = spk_chr(-Gap,
type ="bar"))
spark_df = function(df){
# We need to create an htmlwidget form of the table
out = as.htmlwidget(formattable(df))
# The table also has a requirement on the sparkline package
out$dependencies = c(out$dependencies,
htmlwidgets:::widget_dependencies("sparkline",
"sparkline"))
out
}
spark_df(overall_long_gap_top10)4.3.6 Visualising Rebased Gaps
As well as using the sparkline bar chart to visualise the gap to leader, we can use a similar approach to visualise the gap to other drivers following a rebasing step.
overall_wide_gap_rebased = rebase(multi_overall_wide_gap_top10,
example_driver, stage_codes,
id_col='code')
overall_wide_gap_rebased## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 TÄN -16.7 -32.0 -43.3 -37.2 -37.3 -53.6 -55.7 -63.5 -57.6 -61.5
## 2 ROV -6.1 -11.6 -17.2 -16.0 -13.7 -28.6 -32.4 -39.4 -38.4 -44.0
## 3 NEU -4.3 -2.2 -12.5 -8.0 -2.6 -18.7 -17.5 -37.6 -36.5 -41.7
## 4 BRE -13.1 -15.8 -19.7 -14.8 -8.4 -10.8 -5.1 -10.1 -3.6 -8.9
## 5 EVA 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
## 6 KAT 3.2 6.8 4.2 9.4 15.1 20.9 28.1 30.9 35.6 36.3
## 7 SOL 14.4 13.9 7.2 12.2 14.0 9.1 24.7 23.3 26.6 37.5
## 8 SUN 2.1 2.5 3.6 16.9 33.6 28.5 42.5 45.8 59.7 67.5
## 9 GRE 25.1 33.8 41.4 57.4 74.8 80.7 100.8 118.3 142.9 157.9
## 10 LAP 26.1 56.2 80.1 109.7 148.9 162.2 183.6 225.3 269.5 305.5And now generate the sparklines:
overall_spark_gap_rebased <- overall_wide_gap_rebased %>%
gather(key ="Stage",
value ="Gap", stage_codes) %>%
group_by(code) %>%
summarize(spk_ = spk_chr(Gap, type ="bar"))
spark_df(overall_spark_gap_rebased)4.4 Retrieving Stage Times and Results
This far, we have focused on exploring the overall results data. If required, we can also retrieve detailed results for multiple stages by requesting stage results for a specified list of stages:
multi_stage_times = get_multi_stage_times(stage_list)
multi_stage_times %>% tail(2)## stageTimeId stageId entryId elapsedDurationMs elapsedDuration status
## 539 96810 1749 21571 1301693 00:21:41.6930000 Completed
## 540 96793 1749 21541 NA <NA> DNS
## source position diffFirstMs diffFirst diffPrevMs diffPrev
## 539 Default 52 699224 00:11:39.2240000 153590 00:02:33.5900000
## 540 Default NA NA <NA> NA <NA>We can then cast the data to a wide format and relabel the resulting dataframe.
One recipe for doing this is pretty well proven now, so let’s make it more convenient:
relabel_times_df = function(df, stage_list, cars) {
df %>%
map_stage_codes(stage_list) %>%
map_driver_names(cars)
}And let’s create another function to relabel a dataframe and grab the top 10:
clean_top10 = function(df) {
df %>% relabel_times_df(stage_list, cars) %>%
dplyr::arrange(!!as.symbol(stage_codes[length(stage_codes)])) %>%
head(10)
} We can now get a wide format dataframe containing individual stage times cleaned and reduced to the top 10:
multi_stage_times_wide = multi_stage_times %>%
get_multi_stage_times_wide(stage_list) %>%
clean_top10()
multi_stage_times_wide## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 ROV 968.4 962.7 840.2 547.8 752.5 838.7 548.8 777.1 608.5 602.469
## 2 BRE 961.4 965.5 841.9 551.5 756.6 851.2 558.3 779.1 614.0 602.731
## 3 NEU 970.2 970.3 835.5 551.1 755.6 837.5 553.8 764.0 608.6 602.834
## 4 TÄN 957.8 952.9 834.5 552.7 750.1 837.3 550.5 776.3 613.4 604.114
## 5 OGI 980.5 980.0 842.0 548.5 751.2 853.7 556.7 1364.0 615.0 604.272
## 6 EVA 974.5 968.2 845.8 546.6 750.2 853.6 552.6 784.1 607.5 608.028
## 7 KAT 977.7 971.8 843.2 551.8 755.9 859.4 559.8 786.9 612.2 608.774
## 8 SUN 976.6 968.6 846.9 559.9 766.9 848.5 566.6 787.4 621.4 615.819
## 9 SOL 988.9 967.7 839.1 551.6 752.0 848.7 568.2 782.7 610.8 618.976
## 10 GRE 999.6 976.9 853.4 562.6 767.6 859.5 572.7 801.6 632.1 623.075Or we can get the stage rankings for each stage:
multi_stage_wide_pos = multi_stage_times %>%
get_multi_stage_generic_wide(stage_list,
'position') %>%
clean_top10()
multi_stage_wide_pos %>% head(2)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 ROV 3 2 4 2 5 3 1 3 2 1
## 2 BRE 2 3 5 5 8 6 6 4 7 2Or the gap to stage winner:
multi_stage_wide_gap = multi_stage_times %>%
mutate(diffFirstS = diffFirstMs/1000) %>%
get_multi_stage_generic_wide(stage_list,
'diffFirstS') %>%
clean_top10()
multi_stage_wide_gap %>% head(2)## code SS1 SS2 SS3 SS4 SS5 SS6 SS7 SS8 SS9 SS10
## 1 ROV 10.6 9.8 5.7 1.2 2.4 1.4 0.0 13.1 1.0 0.000
## 2 BRE 3.6 12.6 7.4 4.9 6.5 13.9 9.5 15.1 6.5 0.2624.5 Visualising Stage Times
Two of the most useful chart types, at least in terms of glanceable displays, that we can generate from the detailed stage times over the course of the rally are at the individual level: sparklines showing the individual stage positions and the gap to stage winner.
So let’s start off with those before looking at grouped and individual stage position charts.
4.5.1 Stage Position Sparklines
Our pattern is now pretty well proven so we can routinise our sparkline production:
generate_spark_bar = function(df, col, typ='Gap'){
df %>% gather(key ="Stage",
value =!!typ, stage_codes) %>%
group_by(code) %>%
summarize(spk_ = spk_chr(-!!as.symbol(typ), type ="bar"))
}Let’s see how it works:
multi_stage_long_pos = generate_spark_bar(multi_stage_wide_pos)
spark_df(multi_stage_long_pos)4.5.2 Gap to Stage Winner Sparklines
For the gap to stage winner,
multi_stage_long_gap = generate_spark_bar(multi_stage_wide_gap)
spark_df(multi_stage_long_gap)4.5.3 Stage Position Charts
Let’s reuse the approach we used before for generating the position chart:
multi_stage_long_pos = multi_stage_wide_pos %>%
pivot_longer(c(stage_codes),
names_to ="Stage",
values_to ="Pos") %>%
mutate(Stage = factor(Stage,
levels = stage_codes))
pos_range = 1:max(multi_stage_long_pos$Pos)
ggplot(multi_stage_long_pos, aes(x=Stage, y=Pos)) +
geom_line(aes(group = code)) +
# Invert scale and relabel y-axis
# https://stackoverflow.com/a/28392170/454773
scale_y_continuous(trans = "reverse",
breaks = pos_range) +
geom_dl(aes(label = paste0(' ',code)), # Add space before label
# Add label at end of line
method = list('last.bumpup',
# cex is text label size
cex = 0.5)) +
geom_dl(aes(label = paste0(code, ' ')), # Add space before label
# Add label at start of line
method = list('first.points', cex = 0.5)) +
theme_void()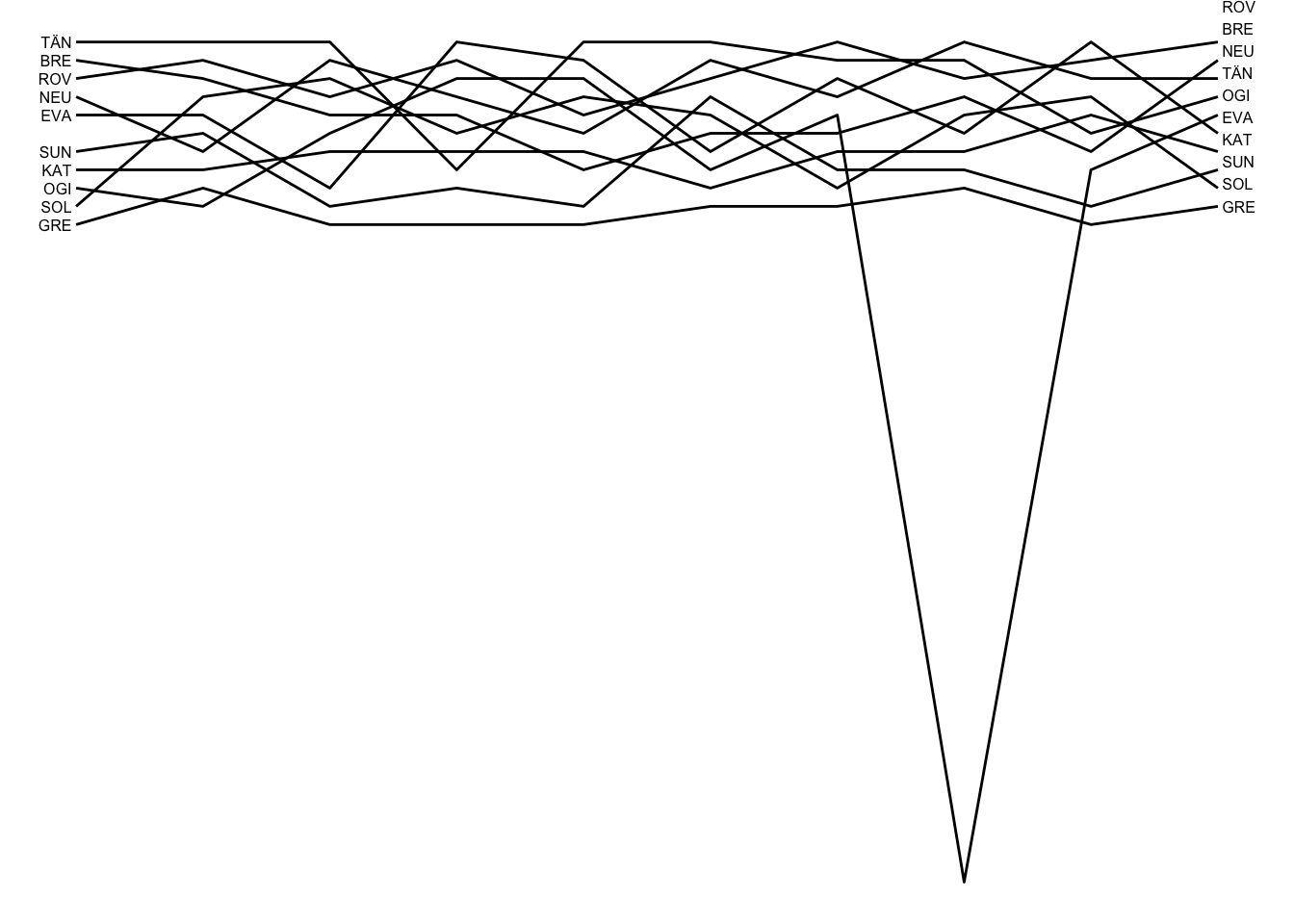
In this case we see the very obvious problem presented by drivers falling outside the typical position range. We really do need to organise this chart by group rank!
4.5.4 Individual Stage position Charts
At the individual level, we can also reuse the approach we developed for charting overall stage positions at an individual level:
get_pos_chart(multi_stage_long_pos, rovCode)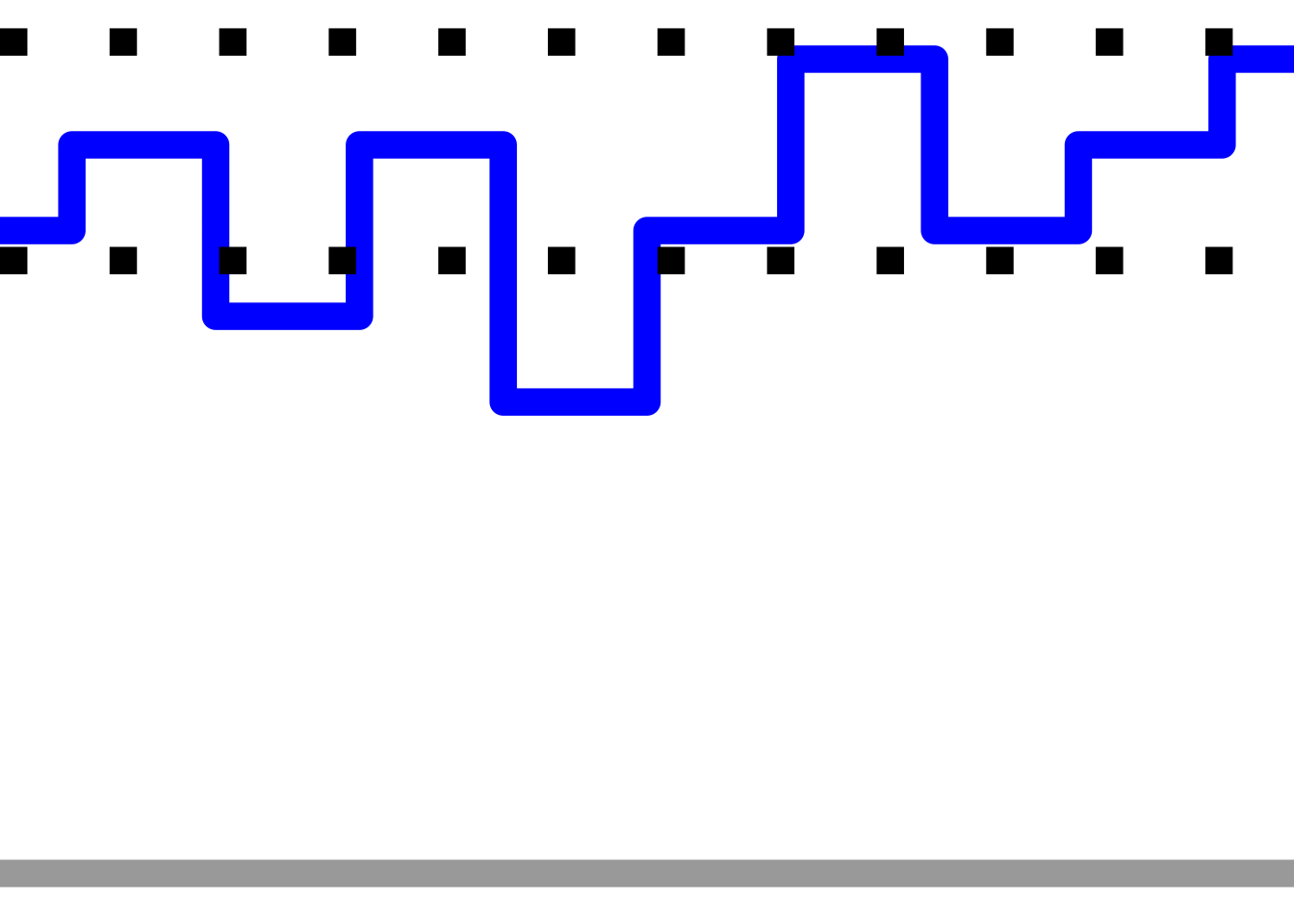
top10_codes = multi_stage_wide_pos$code
gt_stage_pos_plots = list()
# Iterate through each driver in the top 5
for (c in 1:length(top10_codes)){
# Add each plot to the plot list
gt_stage_pos_plots[[length(gt_stage_pos_plots) + 1]] <-
get_pos_chart(multi_stage_long_pos, top10_codes[c],
embed=T, aspect_ratio=3, size=5)
}
multi_stage_wide_pos$poschart = gt_stage_pos_plots
formattable(multi_stage_wide_pos)| code | SS1 | SS2 | SS3 | SS4 | SS5 | SS6 | SS7 | SS8 | SS9 | SS10 | poschart |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ROV | 3 | 2 | 4 | 2 | 5 | 3 | 1 | 3 | 2 | 1 |

|
| BRE | 2 | 3 | 5 | 5 | 8 | 6 | 6 | 4 | 7 | 2 |

|
| NEU | 4 | 7 | 2 | 4 | 6 | 2 | 4 | 1 | 3 | 3 |

|
| TÄN | 1 | 1 | 1 | 8 | 1 | 1 | 2 | 2 | 6 | 4 |

|
| OGI | 9 | 10 | 6 | 3 | 3 | 8 | 5 | 47 | 8 | 5 |

|
| EVA | 5 | 5 | 9 | 1 | 2 | 7 | 3 | 6 | 1 | 6 |

|
| KAT | 8 | 8 | 7 | 7 | 7 | 9 | 7 | 7 | 5 | 7 |

|
| SUN | 7 | 6 | 10 | 9 | 10 | 4 | 8 | 8 | 10 | 8 |

|
| SOL | 10 | 4 | 3 | 6 | 4 | 5 | 9 | 5 | 4 | 9 |

|
| GRE | 11 | 9 | 11 | 11 | 11 | 10 | 10 | 9 | 11 | 10 |

|